Основа
Принцип работы Енота прост: через определенный промежуток времени он выполняет задания, которые Вы ему даёте, и, если результат выполнения задания не совпадает с предыдущим, уведомляет Вас об этом. Задание, как Вы, наверное, уже догадались - это инструкция о том, на какой сайт заходить и какую информацию там искать. И именно тому, как быстро и просто составить эту инструкцию, и будет посвящена большая часть этого руководства.
Где искать?
Итак, как же Енот находит нужную Вам информацию, если она каждый раз меняется? Он запоминает место на странице, куда нужно смотреть, а если точнее - описание этого места. И поскольку пока что существует только ручной режим, Вам полезно будет знать, как указать ему, куда смотреть.
Сейчас я немного расскажу Вам о том, как устроены сайты. Если Вы уже знаете, можете смело пропускать этот и следующий пункт, если же нет, ничего страшного, здесь всё довольно просто.
HTML
Что ж, всё сайты написаны на языке, который называется HTML. Это довольно простой язык, который просто определяет где и в каком порядке будут расположены элементы на странице (ну там блоки с текстом, картинки и всё такое). Как Вы понимаете, эти данные будут очень полезны, если нужно что-либо на этой самой странице найти =)
А теперь перейдём к практике. Нажмите на этом тексте правой кнопкой мыши и в открывшемся списке выберите пункт "Посмотреть код элемента" или подобный (этот пункт обычно расположен ближе к низу). Вы увидите то, что расположено на картинке рядом с этим абзацем.
То, что Вы видите - всё, что Вам необходимо для составления инструкции, которую я описал ранее. Что ж, давайте разберемся, на что мы смотрим. Текст, на который мы изначально кликали правой кнопкой мыши, помещён между этим: "<p>" и этим "</p>". p - это тег (в данном случае означает "параграф"). С помощью него я говорю, что текст внутри - это параграф и оформить его нужно соответственно. После названия тега и до ">" могут также быть указаны дополнительные атрибуты, например, id или class (id="mytag"). Существует куча тегов, но знать их назначение Вам не обязательно. Важно только уметь находить их название и атрибуты.
Хорошо, с тегами разобрались, теперь узнаем каким образом они располагаются на странице. Как Вы уже заметили, они располагаются в виде матрёшки (один внутри другого), и мы можем смотреть, какие теги находятся внутри какого-либо другого тега нажав на треугольник слева от него. И сейчас, когда мы просматриваем наш многострадальный параграф, браузер уже развернул все необходимые теги, чтобы добраться до него.
Находим путь
Осталось только найти путь к нужному нам тегу. Сделать это можно выполнив пять простых шагов:
- Найдите расположение тега среди остальных (как мы делали в пункте выше).
- Учитывайте только то, что находится внутри <body>.
- Игнорируйте все теги, не относящиеся к нужному. Оставьте только развёрнутые (треугольник слева от которых смотрит вниз) и те, которые находятся на одном уровне с нужным.
- Из оставшихся сформируйте цепочку используя слова: внутри, выше, ниже; и указывая порядковый номер: первый, второй... последний, любой.
- Постарайтесь упростить цепочку, исключив из ней необязательные теги: те без которых по пути всё ещё можно будет найти нужный тег.
Сейчас разберём третий и четвертый пункты. Тег может находится внутри другого (это я уже объяснял), или на одном уровне, но выше или ниже
(например: все теги <div> с классом box находятся на одном уровне).
Теперь порядковый номер. Ну, например, абзац, который Вы сейчас читаете - второй в этом пункте, то есть, это второй по счёту параграф.
Что касается пункта "любой", его мы разберём позднее.
Что касается четвёртого пункта, он необязательный, но благодаря ему путь может стать намнооого короче. Например: div с id="content" единственный на странице, так что всё, что идёт до него можем по просу не учитывать, а начать путь сразу с него.
И так, после выполнения всех пунктов, у Вас должен получится примерно такой путь:
внутри 1-й <div>, у которого id равно content ►
внутри 3-й <div>, у которого class равен box ►
внутри 1-й <div>, у которого class равен half ►
внутри 2-й <p>
Первое "внутри" означает, что мы ищем внутри страницы, что логично.

Получаем данные
Сейчас самое интересное. Путь-то мы нашли, а как данные получить? И самое классное то, что мы можем получить любые данные из любого тега в пути, а не только из последнего. То есть, просто дописываем к пути, который у нас уже есть то, что хотим получить, скажем, текст из последнего элемента, и всё, задание готово!
Основная часть
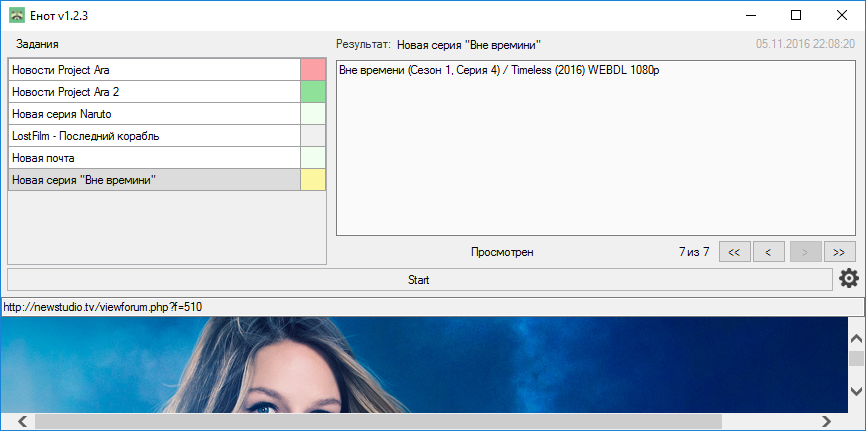
Пришло время описать интерфейс программы. На картинке рядом вы можете увидеть, как выглядит главное окно. Давайте разберём, что в нём находится:
- Слева сверху расположена самая важная его часть - область заданий. В этом прямоугольнике находится список названий и их текущий статус:
выполняется, новых результатов нет, есть новый результат или же во время выполнения задания произошла ошибка.
Для взаимодействия с отдельным заданием выполните правый клик по нему. - Правее - блок с результатами выбранного задания
- Чуть ниже - кнопка Старт/Стоп, которая запускает (или останавливает) автоматическое выполнение заданий.
- Рядом с этой кнопкой - ещё одна кнопка, с помощью которой Вы можете открыть настройки. Их мы рассмотрим в следующем пункте.
- И последний элемент окна - окно браузера, на котором отображается последний сайт, посещённый Енотом.
Что ж, это всё. Если Вам нужна дополнительная информация по этому окну, вы можете найти её по ссылке ниже.
Настройки
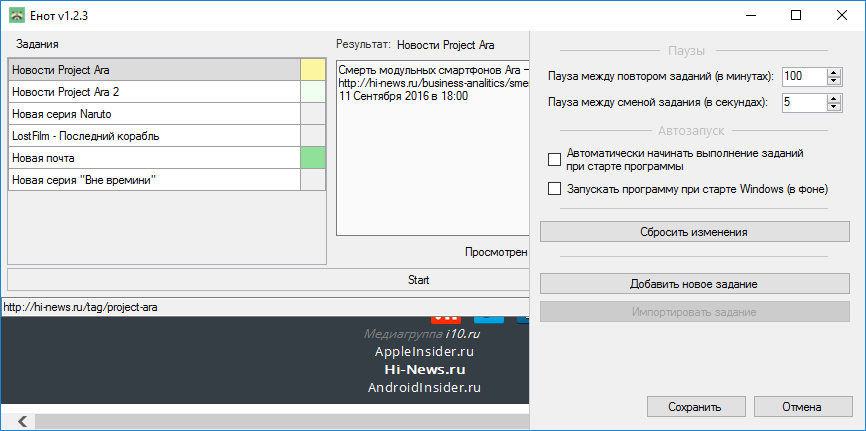
Как Вы помните, если нажать на кнопку с шестерёнкой, откроются настройки. В этом пункте мы остановимся именно на них. Сейчас я опишу те из них, которые могут быть непонятны:
- "Пауза между повтором заданий" - перерыв между повторным выполнением всех заданий.
- "Пауза между сменой задания" - перерыв между завершением выполнения одного задания и началом выполнения другого.
- "Сбросить изменения" - отображение последних сохранённых значений
- "Импортировать задание" - загрузить уже созданное кем-то задание в программу. (будет доступно в следующих версиях)
- Для начала вам нужно создать задание. Как это сделать, будет рассмотрено далее.
- Когда у вас появится задание, откройте настройки внесите необходимые изменения, на своё усмотрение.
- После настройки нажмите кнопку Старт, и программа начнёт работу
- Сверните её, чтобы она больше вас не отвлекала. Енот автоматически сворачивается в трей,
так что советую переместить его иконку на панель задач, как показано на скриншоте ниже:

Шаги 1 и 2
Теперь узнаем, как же всё-таки создать новое задание. Для удобства этот процесс разделён на шаги. Сейчас мы рассмотрим первые два из них:
- Сначала необходимо выбрать название для вашего задания. Чем короче, тем лучше.
- Затем введите сайт, на котором находится нужная вам информация.
- И наконец укажите элемент-контейнер, то есть тег, в котором находится область сайта, с которой Вы будете работать, например, место, в котором расположены все новости, первая из которых Вам нужна. Как указать нужный элемент мы рассмотрим в следующем пункте.
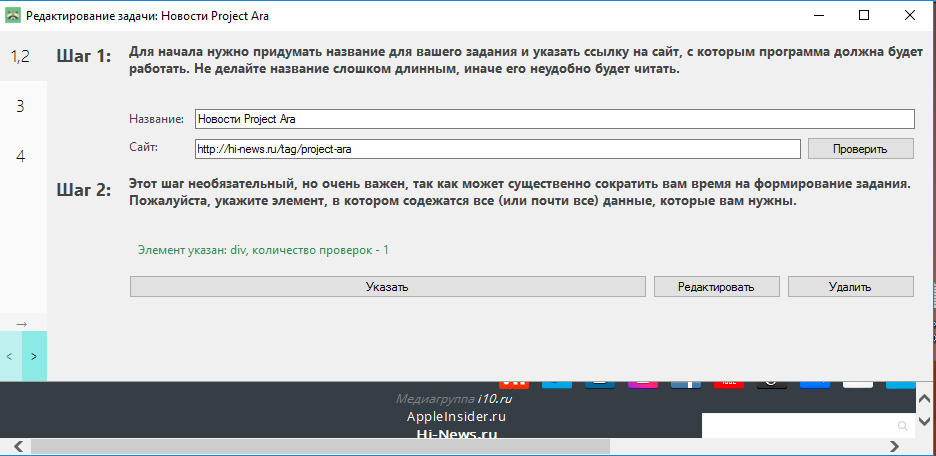
Находим нужный элемент
По сути задание состоит из одного (или более) путей, которые в свою очередь состоят из элементов (тегов) сайта. Так что данный пункт руководства наиболее важен, среди описания интерфейса. Ну что ж, начнём:
- Ознакомитесь с инструкцией по формированию пути, если необходимо.
- Составьте путь.
- В верхний ряд введите основную информацию об элементе (название тега, расположение относительно предыдущего и порядковый номер).
- Далее введите его атрибуты, которые нужно проверить или получить. Программа автоматически определит предназначение каждого из атрибутов. Если Вы не введёте его значение, это значит, что Енот должен получить его самостоятельно (оно будет возвращено как результат задания).
Например: на картинке к этому пункту показано, что нам нужен тег <a> (ссылка), и нам нужно узнать её текст и адрес страницы, на которую она ссылается.
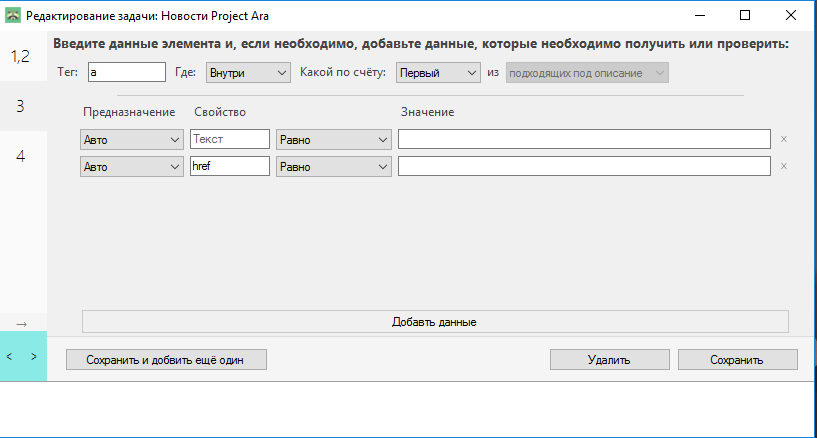
Шаг 3
На этом шаге Вам необходимо указать все пути, которые необходимы, чтобы получить со страницы всё, что нужно.
Как это сделать я уже описывал в предыдущем пункте. Разве что нужно дополнить то, что после создания элемента нажмите "Сохранить и добавить ещё один" для того, чтобы сразу перейти к созданию следующего элемента пути.
Шаг 4
Поздравляю, на этом этапе создание задания завершено! Осталось только проверить, что оно корректно выполняется, сохранить и со спокойной совестью идти пить чай =)
Вступление
В этом разделе я покажу примеры готовых заданий, чтобы проще было разобраться, как создавать свои.
Получаем первую новость
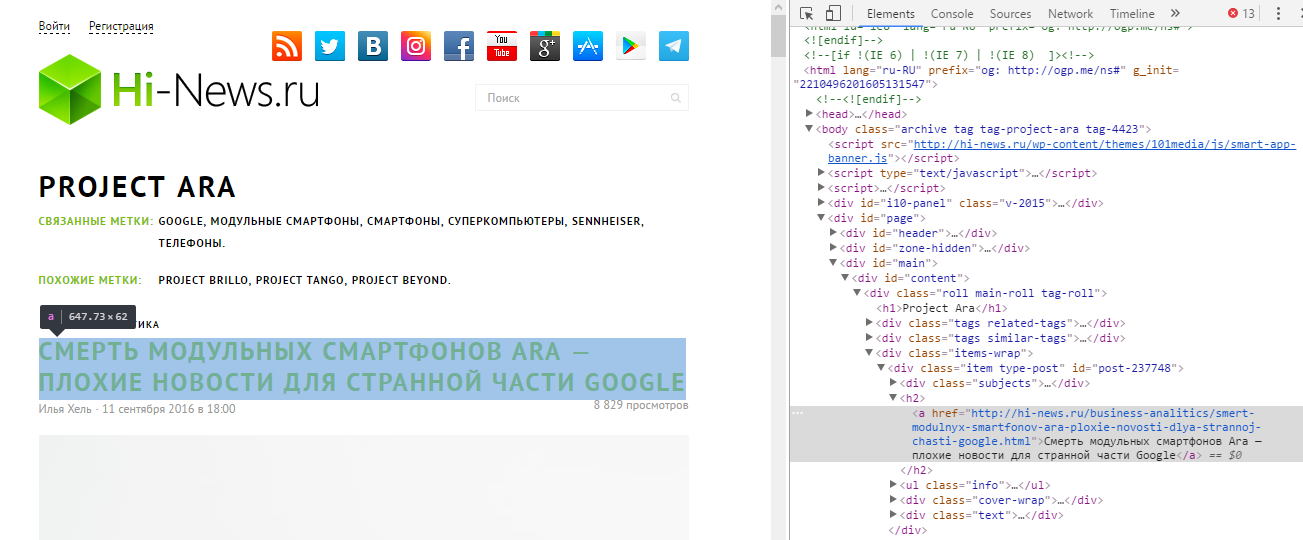
Делать это мы будем на примере сайта Hi-news.ru. Узнаем заголовок поледней новости, ссылку на пост с ней и дату публикации.
Итоговое задание:
внутри 1-й <div>, у которого class равен item type-post (контейнер) ►
Пути:
-
внутри 1-й <h2> ►
внутри 1-й <a>, получить Текст и значение атрибута href - внутри 1-й <li>, у которого class равен lowercase, получить Текст
В итоге, мы получим что-то вроде этого:
Смерть модульных смартфонов Ara — плохие новости для странной части Google
http://hi-news.ru/business-analitics/smert-modulnyx-smartfonov-ara-ploxie-novosti-dlya-strannoj-chasti-google.html
11 Сентября 2016 в 18:00
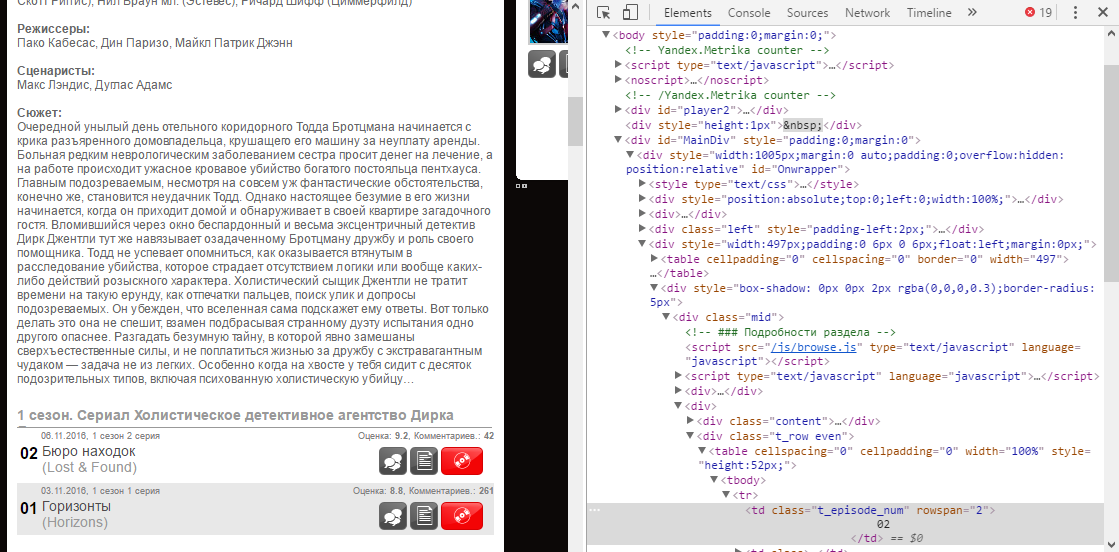
Получаем первую новость: пример 2
Сейчас мы получим последнюю переведённую серию какого-нибудь сериала с сайта LostFilm.tv. Узнаем её номер.
Итоговое задание:
внутри 1-й <div>, у которого class равен mid (контейнер) ►
Пути:
-
внутри 1-й <div>, у которого class начинается с t_row ►
внутри 1-й <td>, у которого class равен t_episode_num, получить Текст
В итоге, мы получим что-то вроде этого:
02
Обратите внимание: Однажды создав подобное задание, вы можете легко преобразовать его для другой страницы этого же сайта. Всё, что требуется сделать - поменять ссылку. Например: Вы можете использовать приведённое выше задание для абсолютно любого сериала, который озвучивает LostFilm, просто укажите нужную ссылку и всё будет работать.
Получаем произвольную информацию на странице
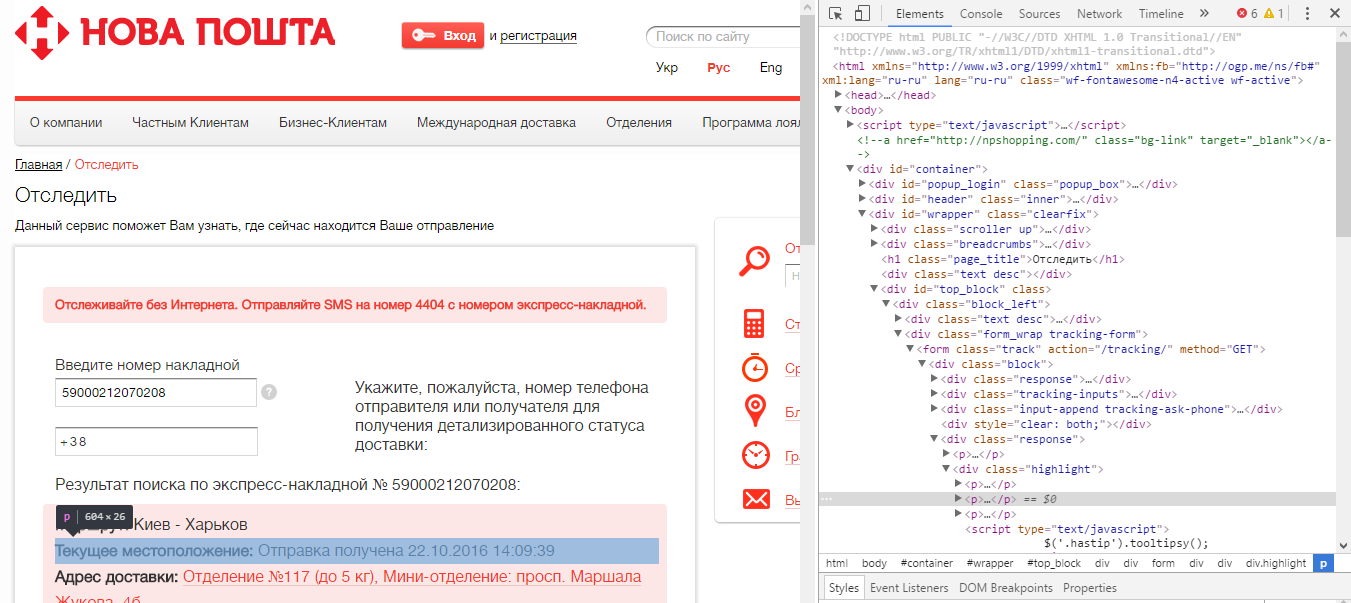
Почтовая служба, которой я обычно пользуюсь, предоставляет возможность отслеживать перемещение отправления. Так почему бы этим не воспользоваться? Итак, сайт: NovaPoshta.ua. Узнаем статус посылки.
Итоговое задание:
внутри 2-й <div>, у которого class равен response (контейнер) ►
Пути:
-
внутри 1-й <div>, у которого class равен highlight ►
внутри 2-й <p>, получить Текст
В итоге, мы получим что-то вроде этого:
Текущее местоположение: Отправка получена 22.10.2016 14:09:39
Получаем новость удовлетворяющую условию
А что если нам удалось получить только полный список новостей, а нам нужны только те, что посвящены определённой тематике? В таком случае, нам нужно перебрать все новости сверху вниз, пока не наткнёмся на ту, что нам нужна. Именно это и делает порядковый номер "Любой".
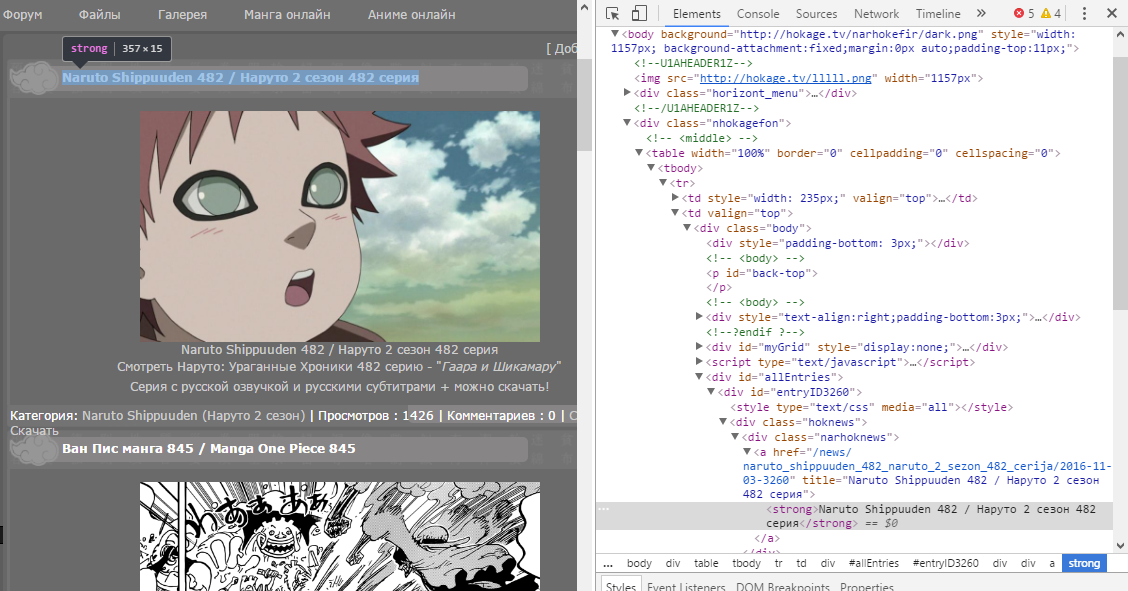
Для примера возьмём сайт Hokage.tv, на нём публикуются озвучки различный аниме, но нас (ну хорошо, меня) сейчас интересуют исключительно новые серии Naruto. Что ж, вперёд, узнаем заголовок этой серии и ссылку на неё.
Итоговое задание:
внутри 2-й <td>, у которого valign равен top (контейнер) ►
Пути:
-
внутри Любой <div>, у которого id начинается с entryID ►
внутри 1-й <div>, у которого class равен narhoknews ►
внутри 1-й <a>, у которого Текст содержит Naruto, получить Текст и значение атрибута href
В итоге, мы получим что-то вроде этого:
Naruto Shippuuden 482 / Наруто 2 сезон 482 cерия
/news/naruto_shippuuden_482_naruto_2_sezon_482_cerija/2016-11-03-3260
Обратите внимание: На каком месте в списке новостей не находилась бы запись, с нужной нам тематикой, именно она и станет результатом данного задания, остальные записи будут игнорироваться.